
Theme 1: Challenging data
The analysis of modern data is faced with various challenges caused by the very rich form in which it is collected. Advances in technology permits the collection of massive amounts of data.
Often those data are of very high dimension, so high that traditional data processing techniques struggle to extract relevant information. Analysing those data efficiently typically requires developing new data compression tools that get rid of irrelevant noise but keep the important information. The data can even be of infinite dimension (for example in the form of curves), and the additional challenge is to find compression algorithms that exploit the continuity of the data.
Modern data are also often collected continuously as a never-ending flow of new observations whose distribution evolves with time, and it is often not possible to store more than just a small fraction of the data. Analysing such data without having to constantly access to the whole flow requires the development of new methods that successively analyse observations from small time windows and aggregate the findings from those small windows in an efficient way.
An additional challenge associated with those sorts of data is that they often evolve not only over time, but also over space. They can consist of multiple observations of surfaces or higher dimensional continuous objects, which are often observed imperfectly, for example with significant gaps. Other data are challenging because they are observed with measurement errors or reported very inaccurately. If this is not accounted for, these errors and inaccuracies typically cause methods to produce biased results. Added to this is the difficulty of identifying causal effects, for example of a treatment.
The goal for ACEMS researchers working in this area is to extract the important information from data and to develop new methods of cleaning, grouping, compressing, denoising, representing, modelling and visualising the data.
The Numbers
Researchers
Cross-Node Collaboration Groups
Industry and International collaboration Projects
People
Key Achievements
Achievements by ACEMS researchers in 2020 include new methods for dealing with big data, highly structured data and novel sources of data.
In a cross-node collaboration, CIs Louise Ryan and Rob Hyndman, together with Research Fellow Stephanie Clark and CSIRO partner Dan Pagendam, published a paper in the International Statistics Review that compared the results of traditional statistical modelling with some modern machine learning strategies that use recurrent neural networks. They showed that with careful modelling, both strategies can perform well, though there are some advantages and disadvantages to both.
CI Rob Hyndman developed forecasting tools that allow for the COVID-19 disruption to time series data such as Australian tourism activity. As part of the forecasting work, Rob put together an ensemble forecast that combines forecasts from multiple models to get an overall forecast. One of the models he included was from an ACEMS team including AI Josh Ross, PhD student Dennis Liu and AI Lewis Mitchell. Their model included Google mobility data about how people are mixing and interacting. It also included regular survey responses from people in Australia’s capital cities about their compliance to guidelines, like the 1.5-metre social distancing rule.
Rob Hyndman also developed new methods for anomaly detection in high-dimensional and streaming data. This was cross-nodal collaboration with Kate Smith-Miles. Rob also developed new methods for high-dimensional forecast reconciliation and developed new methods for exploring probability distributions disaggregated by calendar granularities.
The use of crowdsourced information to support scientific studies has surged in recent years. There are now hundreds of ‘citizen science’ projects in fields ranging from astronomy to ecology. ACEMS researchers AIs Edgar Santos-Fernandez, Julie Vercelloni, Erin Peterson and CI Kerrie Mengersen have been working with ACEMS Partner Organisation, AIMS, and with other external organisations and collaborators, to develop new methods to address concerns over the accuracy of such data. These statistical models estimate a user’s latent ability, which can lead to more trustworthy analyses and personalised citizen science training programs.
Remote sensing devices are used in many disciplines, ranging from health (medical imaging) to earth observation (satellites, drones). The increasingly fine-scale images and other data obtained from these devices have great potential to provide new solutions for challenges such as cancer and conservation, but they also create challenges because of the increased size of the datasets and complexity of the analyses. ACEMS PhD student Jacinta Holloway-Brown, Research Fellow Insha Ullah and CI Kerrie Mengersen have been collaborating with the United Nations Global Working Group to develop methods to use Earth Observation (EO) data to help Official Statistics agencies around the world monitor Sustainable Development Goals (SDGs) such as food production, water quality and poverty. They have also been collaborating with the Queensland State Government to use EO data to detect biosecurity incursions such as fire ants, and with radiologists in local hospitals to improve radiotherapy treatment through more precise analysis of medical scans.
ACEMS AI Edgar Santos-Fernandez and CI Kerrie Mengersen, with researchers (Antonietta Mira, Francesco Denti) have been working with international colleagues to develop methods to identify the low-dimensional level of information in high-dimensional data. This ‘intrinsic dimension’ (ID) can be used as a measure of complexity in the data. The new method is based on comparing the ratio of distances between the first and second order neighbours of each observation and allows the ID to vary locally across the space of the data. The approach was applied to basketball data to gain insight into the complexity of plays by different teams.
AI Anthony Mays worked with Outreach Officer Anita Ponsaing and Gregory Schehr from the University of Pierre and Marie Curie in Paris, on the calculation of the skew-orthogonal polynomials and the Tracy-Widom distribution which was completed in 2020 and accepted for publication in the Journal of Statistical Physics in December.
Understanding the causal effect of a treatment or a policy from observational studies is of great interest in economics, social science and public health. There, a major challenge is confounding where individual characteristics are related to both the treatment selection and the potential outcome, so that the casual effect is not directly identifiable from the data. Early literature focused on binary treatment variables which indicate whether an individual receives the treatment or not. In many applications, however, the treatment variable is continuously valued, can be measured only with error, and its causal effect is of great interest to decision makers. For example, in evaluating how fat intake affects the risk of developing breast cancer, the causal effect of interest depends not on the introduction of the fat but on how much it is taken. The daily fat intake data are usually measured from a single 24-hour recall and it is known that a large proportion of the variance of the data is made up of measurement error. The confounding issue and the measurement error together make existing techniques not directly applicable. Finding a proper modification is challenging. Collaborating with Dr Zheng Zhang, an assistant professor from Institute of Statistics & Big Data, Renmin University of China, AI Wei Huang constructed a nonparametrically consistent estimator of the average dose-response function of continuous treatment when the treatment data are measured with error. They also developed unified specification tests of commonly used continuous treatment models. They are further investigating ways to test heterogeneity of continuous treatment effects, that is to test if the treatment effect conditional on certain covariates is identical for all subpopulations, from such challenging data.
AI Miranda Mortlock and team have been working on taking observed data from a commercial crop and looking at modelling of plant growth and yield. Data from multiple sites has been examined for harvesting and transport to the packing and distribution sheds. The team has been looking at various perspectives.
AI Di Cook led a team which included her honours student Weihao (Patrick) Li and Emily Dodwell, Principal Inventive Scientist at ACEMS Partner Organisation AT&T, working on statistical modelling of bush fires in Victoria. They took hotspot data from the Himawari-8 satellite, which shows heat source locations over time and space, and filtered out hotspots that were unlikely to be bush fires. They then used their new data mining algorithm to do spatiotemporal clustering where they introduced a time to dimension to geographic data to estimate ignition time and location. They supplemented that information with data such as temperature, rainfall, wind, fuel load, and distance to campsites, roads, and Country Fire Authority (CFA) stations that they collected from other sources. They used a machine-learning algorithm called a random forest to analyse historical bushfire data from Victoria’s Department of Environment, Land, Water and Planning from 2000 through the summer of 2018-19 and used statistical modelling to predict the cause of bush fire. A notable conclusion was that lightning sparked more than 80 per cent of bush fires in Victoria and arson could only be blamed for about four per cent of the fires.
ACEMS Research Fellow Dorota Toczydlowska, in collaboration with Dr Tuan Nguyen of the Bone Biology Division, Garvan Institute of Medical Research and CIs Louise Ryan and Matt Wand received encouraging reviews at the journal "Statistics in Medicine" for their paper on genetic association studies and bone loss. The data from the Dubbo Osteoporosis Epidemiology study are challenging in a number of ways, but particularly since they involve expression measurements on several dozen single nucleotide polymorphisms and heterogeneity of measurements. The team addressed the challenges by incorporating various random effect structures.
Research Fellows Luca Maestrini and Dorota Toczydlowska, in collaboration with University of Technology Sydney practicum doctoral student, Emanuele Degani, derived mean field variational Bayes algorithms for fitting non-nested random effects structures that are manifest in the Dubbo Osteoporosis Epidemiology Study.
CI Aurore Delaigle worked to develop new statistical methods for clustering functional time series, where each series consists of observations of the same functional object over a period of time. A typical source of functional time series data are sensor networks, where each sensor produces a functional observation each day (for example traffic flow trajectory throughout the day). Over a certain time period (for example a year) her team obtained a series of functions from each sensor. The goal of clustering is to organise the observations into groups of functions that have similarities, which can help uncover structure in the data. Aurore’s team has gone on to develop and experiment with a new efficient algorithm for clustering functional data.
In another example of cross-node collaboration, Research Fellow Xihui Fan with supervisors ACEMS AI, Hongbo Xie and CIs Scott Sisson and Kerrie Mengersen, produced a paper on Bayesian Nonnegative Matrix Factorization with Dirichlet Process Mixtures. The work is at the interface of statistics and machine learning, and focuses on identifying a low-dimensional representation of high-dimensional data. These methods are employed in a very wide range of problems, across astronomy, computer vision, cybersecurity, bioinformatics, etc. They plan to extend this work in 2021, to a federated learning environment and expand the research team include colleagues in computer science at both the UNSW and QUT nodes.
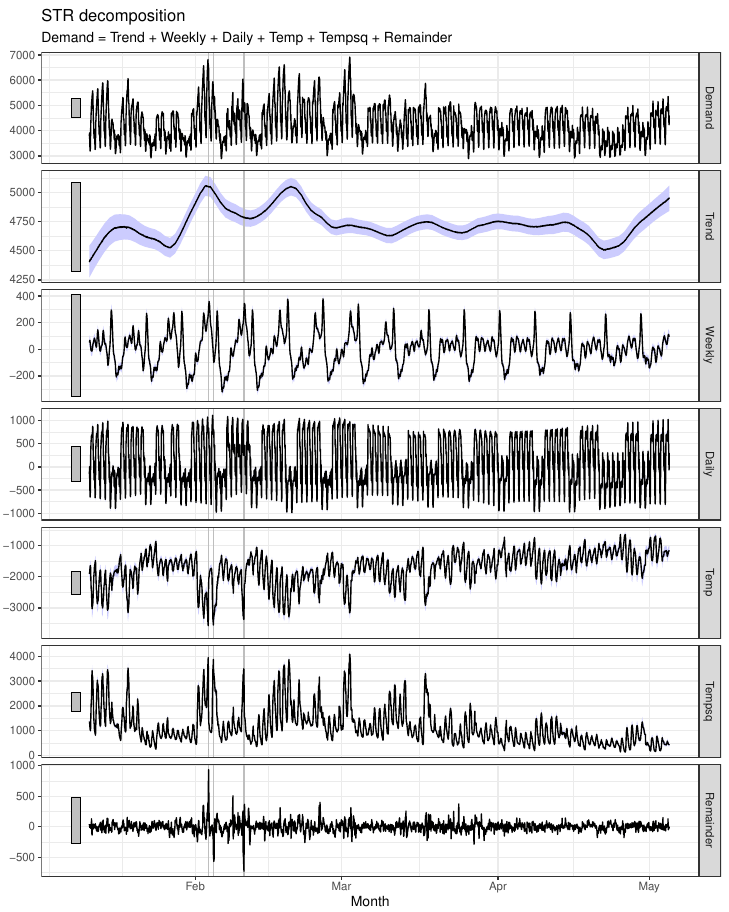
Electricity demand decomposition based on various seasonalities and temperature effects. The STR (a Seasonal-Trend decomposition procedure based on Regression) proposed here is the first time series decomposition method that allows for complex seasonal topology.
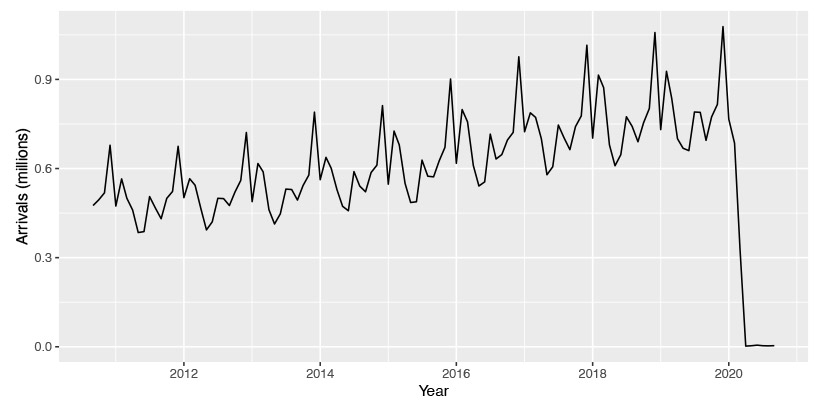
Shows the effect of COVID-19 on international arrivals to Australia.
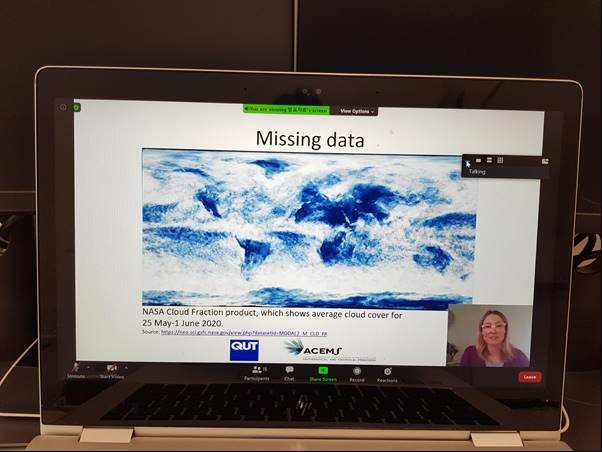
Jacinta Holloway-Brown presenting her work at the United Nations Big Data Conference in 2020. Her research focuses on new statistical machine learning methods to deal with the challenge of cloud cover in satellite data.
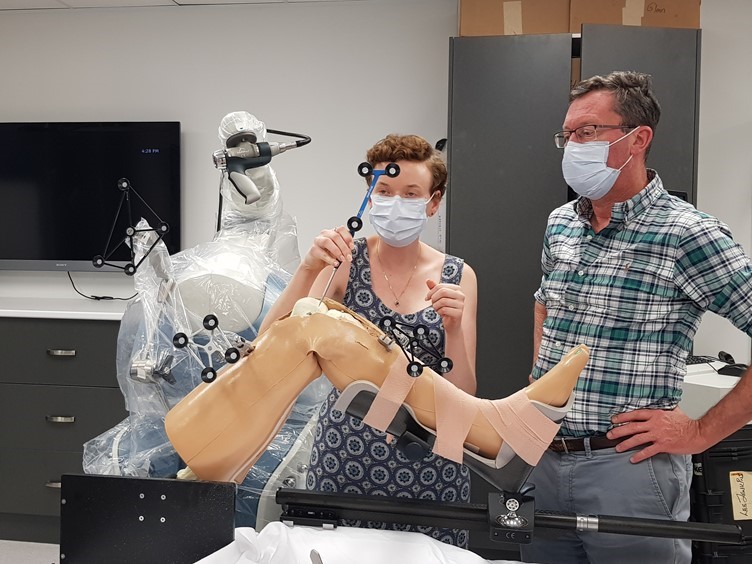
Going to the source of the data: QUT researchers including ACEMS members (not pictured) in the Stryker lab in Brisbane, learning from surgeon Dr Ross Crawford about Stryker’s robotic support for knee replacement surgery, to help understand medical imaging data.




Examining phenology, row crop with irrigation lines, counting plant population, workshopping results.
Plans for 2021
Plans for 2021 are already well underway, and the following is a brief summary of what some ACEMS researchers across Australia are planning to do:
- Work with bore water modelling, particularly to develop multi-bore models that account for spatial and temporal correlation between the various bores and over time. Using Bayesian approaches (specifically Bayesian LSTM models) to facilitate the handling of missing data (Ryan)
- Develop tools for dimension reduction in a space of high-dimensional probability distributions (Hyndman)
- Develop nonparametric tools for measuring the time for a river to flow between two sites based on sensor data. Cross-nodal collaboration. (Hyndman)
- Continue to develop methods to improve the use of, and trust in, crowd-sourced data (Mengersen)
- Continue to improve methods to manage and analyse data from medical and earth observation devices (Mengersen)
- Continue to develop insights into the innate complexity, or intrinsic dimension, of high-dimensional data (Mengersen)
- Develop models of distribution from field to packing shed (Corry, Sisley)
- Develop a statistical model for plant growth using meteorological conditions during the season (Mortlock)
- Continue the exploration of production data (Mortlock)
- Extend work on identifying a low-dimensional representation of high-dimensional data to a federated learning environment (Xie)